朝花夕拾
架构相关
playcenter
主从模式
-
注意,从playcenter也会监听MessageHub的消息Emit,所以不应该在从playcenter上的Listen处理函数应该判断是否是主playcenter:
if not g_ServiceMgr:IsMasterScheduler() then return end
模块相关
DBProxy的使用
Define
自定义Query
MessgeHub
Define
- game\common\lua\messagehub\MessageDefine.lua
Use
Important
伏羲服务以及伏羲长连接
Use
CStore框架
时序
CompetitionFlow
Joiner
Node
与gameplay的数据交互
体素化
什么是体素化
- 类似2D格子/像素点,体素数据是3D划分后的每个小格子里的体素数据,可以有坐标、障碍、材质、标记等信息,用于上层应用(运动校验、进出区域等)
为什么要体素化
客户端的刚体碰撞体信息服务器没有。客户端需要将体素化数据同步给服务器
不做体素化是不是也可以,直接把刚体信息告诉服务器也可以
客户端对象(RenderObject、Lua对象、引擎对象);服务器对象(Lua对象、引擎对象)
运动碰撞校验;进出区域(公共场景、玩法场景如禁马区);
体素化数据结构(TCoreGrid)
如何获得体素化数据
制作美术(美术):场景搭建,模型prefeb,添加刚体
导出刚体(C#):三角网格数据的导出
场景体素化(静态)(C++)由刚体生成体素化数据:读取,PxPhysicsAPI重建场景,射线采样,解析,
静态体素数据应用中解决的问题:洞穴问题;海水问题;河流湖泊问题(复杂不规则的河流湖泊水域,模拟刚体,利用水碰撞和下方的碰撞的高度差决定当前坐标下水的深度);瀑布水帘洞问题(河流切片,给瀑布打上不一样的标记,不做抬高)
动态体素化数据:庄园、动态平台、化学物品
体素数据相关的优化:
内存:调色盘数据结构(RnRIndex)
存储:边界:小副本支持给体素化数据刷边界信息,无需加载玩家不可达的边界区域的体素数据
网络:
踩坑经验
物品相关
退还道具
- 创建出来的道具带有ExtraData,包含了交易冷静期等额外数据。要么功能逻辑上避免给玩家退道具,要么消耗道具时保存物品的ExtraData,然后在退还道具时再生成同样的道具。不能用物品的TemplateId直接创建出缺失了额外信息的新物品退还给玩家
界面相关
界面深度
- 开发试炼擂台界面的时候出现了摇杆界面遮挡试炼擂台界面的问题。在Unity排查界面深度的值,发现试炼擂台界面的深度比摇杆界面的深度深。最后更改了UIOpen监听的消息和时机,让试炼擂台界面很晚创建,深度就正确了。
调试相关
查看pdef类、Lua类的成员
成员变量:直接print
pdef类成员函数:print生成的Lua类对象的metatable
e.g.
local example = CCppExploreData:new() ppp(getmetatable(example))Lua类成员函数:直接print类名
底层相关
Lua
API划分
全局状态机和内存管理
字符串
Table
数据结构
typedef struct Table {
CommonHeader ;
lu_byte flags ; /* 1<<p means tagmethod (p) is not present */
lu_byte lsizenode ; /* log2 of size of `node ' array */
struct Table * metatable ;
TValue * array ; /* array part */
Node * node ;
Node * lastfree ; /* any free position is before this position */
GCObject * gclist ;
int sizearray ; /* size of `array ' array */
} Table ;
table数组部分和哈希表部分分开存储
操作哈希表的时间复杂度可以认为是
table的数组部分存储在中,长度信息存于;哈希表部分存储在中,哈希表的大小一定是2的整数次幂,幂次存于lsizenode
每个table,最多会由三块连续内存构成。一个Table结构;一块存放了连续整数索引的数组;一块大小为2的整数次幂的哈希表
有一个只读的全局变量dummynode,空表被初始化时,node域指向这个dummy节点,用来减少空表的维护成本
算法
创建
查询
迭代
获取长度
元方法
lua中复杂的数据结构大量依赖给table附加一个metatable来实现
查询特定元方法是否存在是运行期效率的热点,否则每次操作至少要多做一次hash查询
table存储结构中的flags域记录了哪些元方法不存在。当充当元表的table被修改时,会清空flags重新做元方法查询,结果就缓存在flags标记位中
每个元方法名字都在state初始化时生成了字符串对象
函数与闭包
函数原型
- 闭包可以理解为把一组数据绑定到特定函数上
Upvalue
- Upvalue指生成闭包时,与函数原型绑定在一起的外部变量
语法特性(syntacic sugar)
- 函数调用时,如果参数只有一个,且这个参数是一个字符串字面量或者是table字面量(即table构造式),则可省略括号。
协程及函数的执行
LuaJIT
Just-In-Time
什么是即时编译:A JIT compiler runs after the program has started and compiles the code (usually bytecode or some kind of VM instructions) on the fly (or just-in-time, as it's called) into a form that's usually faster, typically the host CPU's native instruction set. A JIT has access to dynamic runtime information whereas a standard compiler doesn't and can make better optimizations like inlining functions that are used frequently.
This is in contrast to a traditional compiler that compiles all the code to machine language before the program is first run.
To paraphrase, conventional compilers build the whole program as an EXE file BEFORE the first time you run it. For newer style programs, an assembly is generated with pseudocode (p-code). Only AFTER you execute the program on the OS (e.g., by double-clicking on its icon) will the (JIT) compiler kick in and generate machine code (m-code) that the Intel-based processor or whatever will understand.
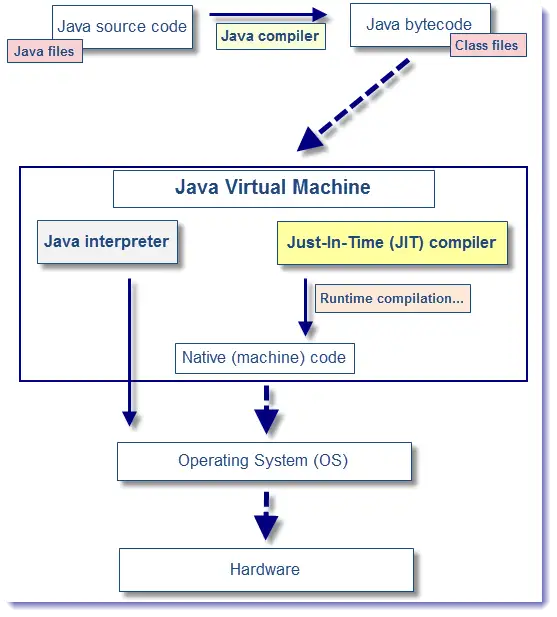
无论是C、C++、Java这种静态需要编译的代码,还是Lua、JS这种动态解释代码,都是以某种方式转变成一堆堆的二进制代码来交给电脑运算的,但区别是:
C、C++是通过平台专属编译器来将代码编译成CPU可以直接执行的二进制代码,因为CPU有许多不同的架构,比如x86、AMD64、ARM、MIPS等等,这些不同的CPU所需要的二进制代码格式都不相同,所以每一个平台专属的二进制指令被限定了只能在该平台执行。
Java编译器直接将Java代码编译成Java字节码,每一个平台专属一个虚拟机,用来模拟CPU执行指令。无论CPU是什么,我自己开发的虚拟机可以统一指令格式,这样Java就可以编译一次然后在各种不同平台运行。但这样做的代价就是本来一条指令CPU只需要运算一次,但是由于虚拟机内部还需要有自己的逻辑,所以就会造成每条虚拟机指令所需要的CPU指令成倍增长,造成运算速度成倍下降。
Lua、JS与Java的执行过程大致是相同的,只是Java是强类型,静态语言,一次编译完成后再执行(一处出错就不能通过编译)。而Lua、JS则是弱类型,可以一边解释,一边执行(后面语句出错不会影响前面的执行)。而JIT则绕过了虚拟机,尽量把原始代码直接翻译成平台专属的字节码在CPU中直接执行。绕过虚拟机的同时就绕过了虚拟机内部许多不需要的逻辑,所以就成倍提升了代码的运行效率。
FFI
- 常用接口说明:FFI · OpenResty最佳实践
评论
发表评论